






















 Italy
Italy France
France India
India UAE
UAE Germany
Germany Russia
Russia Malaysia
Malaysia Spain
Spain United States
United States Malta
MaltaUnderstanding Explainable AI: Architecture, Techniques, Benefits, and Future Trends
Understanding Explainable AI: Architecture, Techniques, Benefits, and Future Trends
AI systems now approve loans, detect cancer, and drive cars — yet most people have no idea how they actually reach a decision. That is the problem Explainable AI was born to solve. This guide explains everything, starting right from the basics.
Black Box Problem
Imagine you walk into a bank and apply for a loan. The bank manager feeds your details into a computer. Two seconds later, a red light flashes: Denied. You ask, "Why?" The manager shrugs and says, "The computer said so." No reason, no explanation, no way to appeal.
This is not science fiction. This is what millions of people experience today, every single day, because of AI systems that nobody — not even the engineers who built them — fully understands.
These systems are called black boxes. You put data in one side, decisions come out the other side, and what happens in between is a complete mystery. And that mystery is becoming one of the biggest problems in technology.
Deep learning models — the kind that power facial recognition, medical imaging, fraud detection, and language AI — are made of hundreds of millions of mathematical operations stacked on top of each other. Even the researchers who design them cannot always trace exactly why the model made a specific decision. The model simply learned from data and produced an output.
For low-stakes applications, that's fine. A bad Netflix recommendation costs you 90 minutes. But when AI is deciding whether someone gets bail, whether a tumor is malignant, or whether a car should brake — the inability to explain that decision stops being a technical inconvenience and becomes genuinely dangerous. That's the black box problem, and that's exactly where it matters.
Read Also: Generative AI Vs. Agentic AI - Key Differences, Characteristics, and Use Cases Explained
What Is Explainable AI?
Explainable AI (XAI) is a collection of methods, tools, and techniques designed to make the decisions and outputs of AI systems understandable to humans. Rather than just giving you an answer, an XAI-powered system also shows you why it reached that answer, what factors it considered most important, and how confident it is.
Think of it as the difference between a GPS that just says "turn right" and one that says "turn right because the main road is congested, this route saves 8 minutes, and it avoids a school zone." The second GPS is doing the same navigation job, but it gives you the reasoning — and that reasoning builds trust.
Technical Definition
XAI is not a single algorithm. It is a layer of interpretation that sits on top of — or is built into — AI models. Its goal is to produce human–interpretable outputs alongside AI predictions, so that both the end user and the developer can audit, understand, challenge, or improve the model's decisions.
Explainability vs. Interpretability: These Are Not the Same Thing
Several people treat these terms as synonyms. They are not, and the difference is very important in practice.
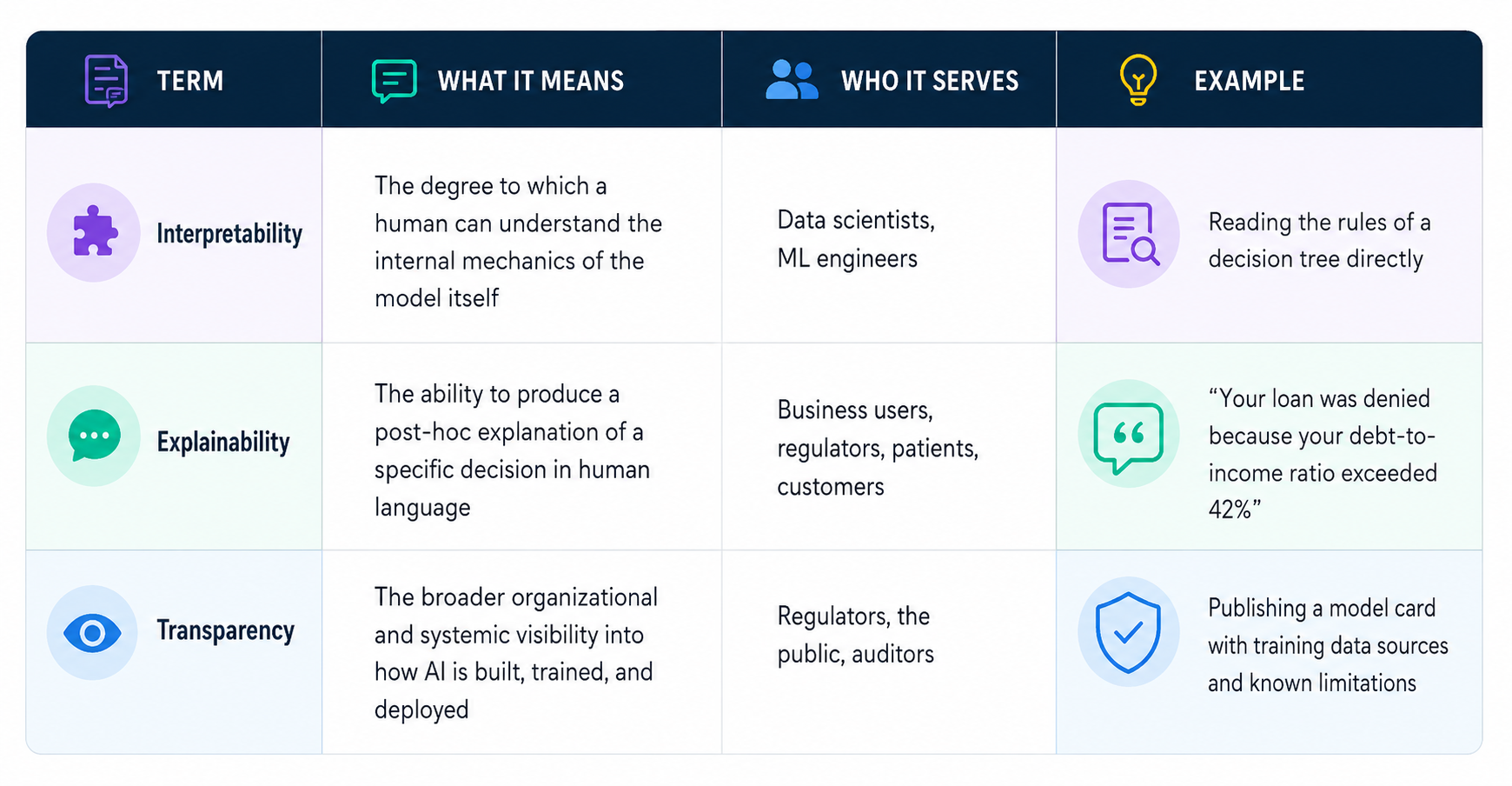
The goal of XAI is to deliver all three — but different techniques achieve different levels, and knowing which you need is the first step to choosing the right tool.
Why Explainable AI Matters: Real-World Stakes Are Enormous
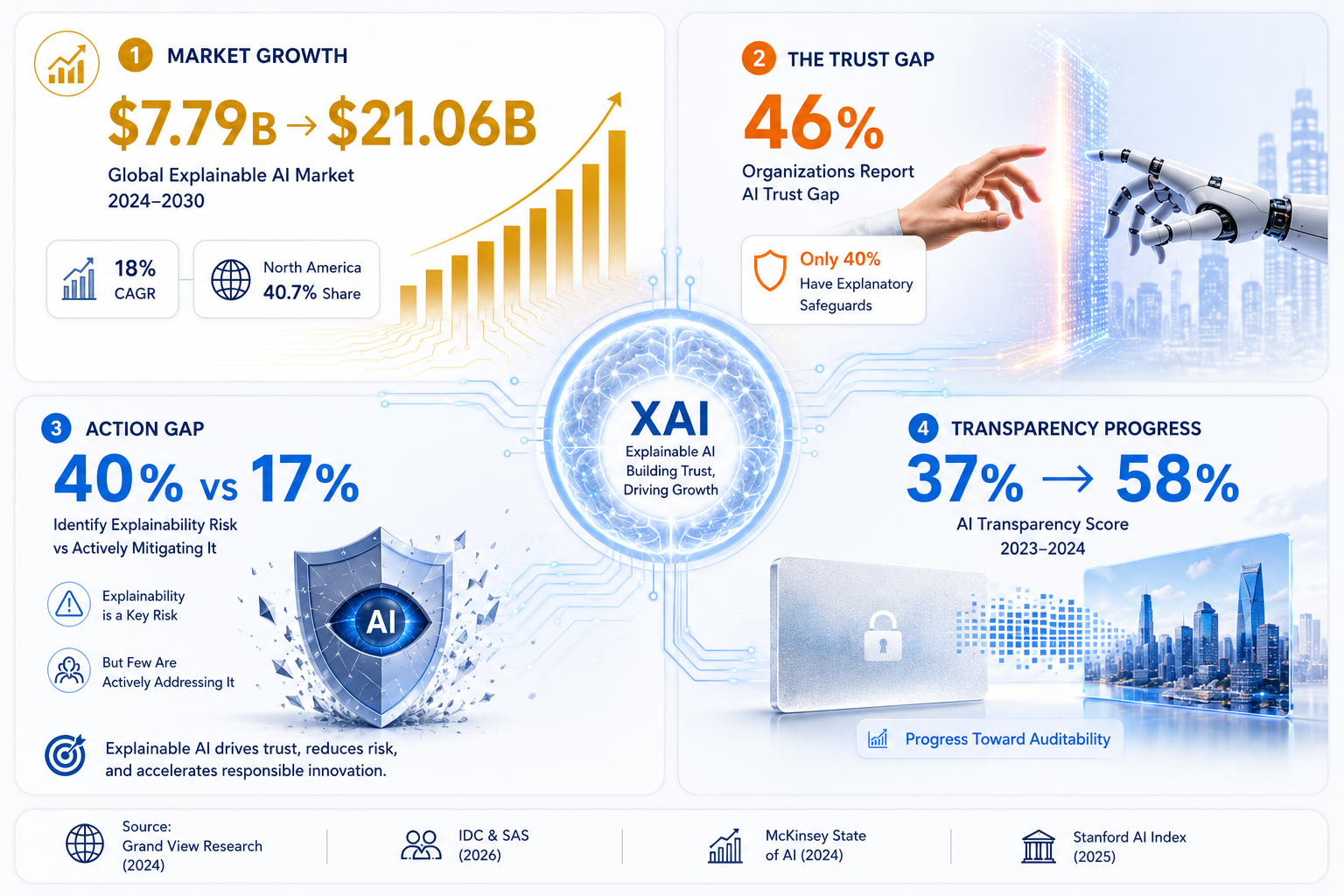
XAI is not just a technical nicety. There are four major, concrete reasons why the world urgently needs it — and why companies that ignore it are taking on serious risk.
- Trust — Without Explanation, AI is Just Guessing Out Loud
People don't trust what they can't understand — that's just human nature. A 2024 study on medical AI found patients were significantly more willing to follow AI recommendations when the system explained its reasoning, not just handed them a number. An AI that can't show its work loses the confidence of everyone depending on it.
- Regulation — Governments Are Now Requiring It
The EU AI Act classifies AI used in healthcare, credit scoring, hiring, and law enforcement as high-risk — and mandates transparency documentation, technical explainability, and human oversight. The US FTC has pushed the same direction in consumer finance. JPMorgan Chase has committed to real-time explainability across all AI-driven financial products. This stopped being optional the moment legislation arrived.
- Bias Detection — Explanations Surface What Nobody Meant to Build In
Some of XAI's most valuable work is catching bias that crept in quietly. When you trace how a model reaches its decisions, you sometimes find it learned the wrong shortcuts — zip codes standing in for creditworthiness, certain names flagging higher hiring risk. Without explainability, those patterns stay invisible. With it, they can actually be fixed.
- Debugging — You Can't Fix What You Can't See
High accuracy on test data doesn't mean the model is reasoning correctly. A well-known example: a medical AI trained to detect pneumonia from chest X-rays was quietly using the presence of a portable X-ray machine as a signal — because in the training data, portable machines only appeared with the sickest patients. The model looked fine on paper. XAI caught the shortcut before deployment. Without it, that flaw goes live.
Industry Insight
XAI is also an economic tool: Companies that can explain their AI decisions to regulators and customers face fewer legal challenges, earn higher customer trust, and can iterate on model improvements far faster than those operating blind. The transparency dividend is real and measurable.
Two Families of XAI: Ante-hoc vs Post-hoc (And Why It Changes Everything)
Before you pick an XAI technique, you need to understand a fundamental architectural choice. Explainability can either be baked into the model from the start, or bolted on afterward. These are called ante-hoc and post-hoc approaches, and they represent very different trade-offs.
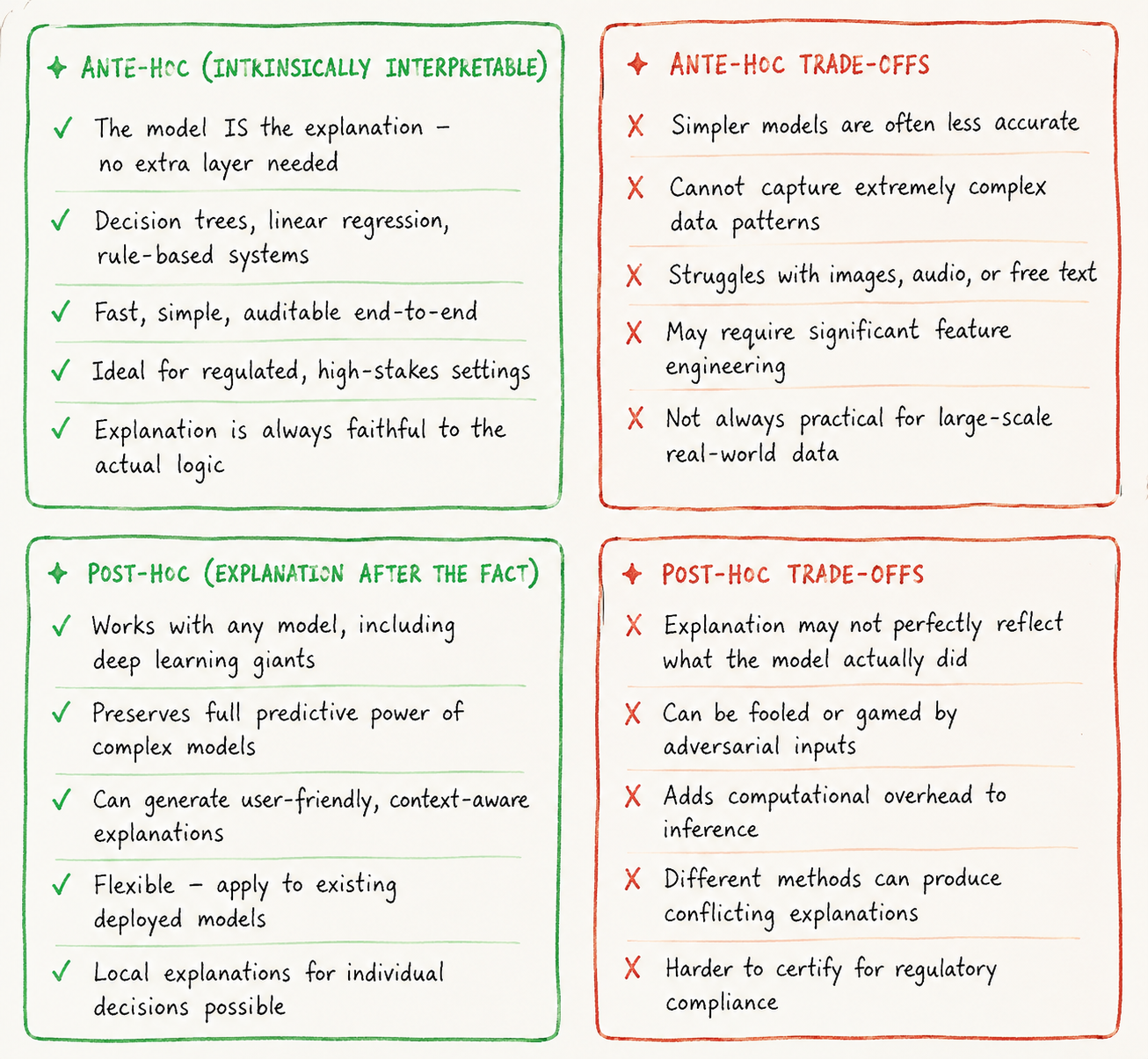
There is also a second axis: whether a method is model-agnostic (works with any black box model) or model-specific (designed for a particular type of model like a neural network). Understanding where your tool sits on both axes — ante/post and agnostic/specific — is the foundation of choosing correctly.
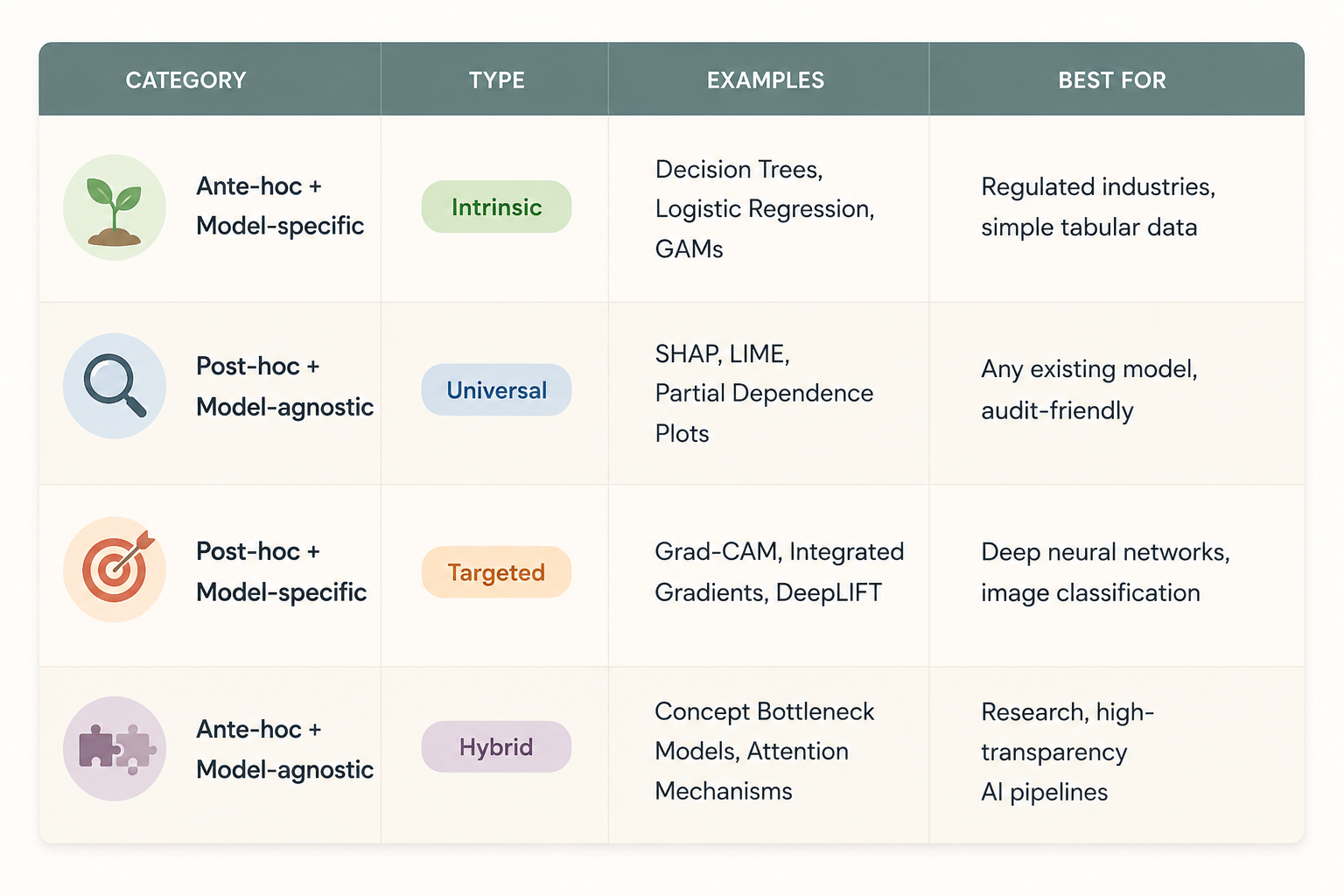
Core XAI Techniques Decoded: SHAP, LIME, Grad-CAM, and More — Explained Simply
This is where most XAI articles get abstract and lose people. We are going to do the opposite. Here is every major technique explained with a simple analogy, what it actually does under the hood, when to use it, and what it cannot do.
SHAP — SHapley Additive exPlanations
SHAP is currently the gold standard in XAI for structured/tabular data. It answers the question: "How much did each input feature contribute to this specific prediction?"
The Group Project Analogy: Imagine five people working together on a group project that ends up winning a major client. SHAP tries to figure out how much each person actually contributed to that success. It does this by testing every possible combination of team members and measuring how the outcome changes when one person is added or removed. The method comes from cooperative game theory, specifically Shapley values developed by economist Lloyd Shapley, which were originally designed to contribute rewards fairly based on individual contribution.
In AI terms: SHAP evaluates your model across all possible subsets of input features and assigns a contribution score to each feature for a given prediction. A positive SHAP value means the feature pushed the prediction up; a negative value means it pushed it down.
Key properties: SHAP is consistent (if a feature becomes more important, its score will always increase), locally accurate (the sum of all SHAP values equals the prediction), and both local and global (it can explain a single prediction or the entire model's behavior). The solution is mathematically unique — run SHAP twice on the same input and you get the same answer.
Technical Note
The computational challenge of SHAP: calculating true Shapley values requires 2n model evaluations (where n is the number of features). For a 20-feature model, that's over a million evaluations. Practical SHAP implementations like TreeSHAP use model structure to approximate this efficiently — linear time for tree-based models. This is why SHAP is fast on gradient boosting but slow on large neural networks.
Read Also: What is Autonomous AI? Capabilities, Architecture, and Enterprise Risks
LIME — Local Interpretable Model-Agnostic Explanations
LIME takes a different and ingenious approach. Instead of trying to understand the whole model, it asks a much simpler question: "If I slightly change the input, how does the output change?" And from those changes, it builds a simple, local explanation.
The Local Map Analogy: The whole map of a country is too complex to read at once. But if you zoom in to one city, you can draw a simple, accurate street map. LIME does the same thing — it zooms into one prediction, generates hundreds of slightly modified versions of that input, observes how the model responds, and then fits a simple linear model (like a straight line through the data) to approximate the complex model's behavior in that tiny region. That simple model is your explanation.
How it works technically: For a single input x, LIME generates a neighborhood of perturbed samples (e.g., randomly removing words from a sentence, masking pixels in an image, or perturbing numerical feature values). It then weights each perturbed sample by proximity to x and fits an interpretable model (linear regression or a decision tree) to predict the black-box model's output on those samples. The result is a set of feature importance scores that are only valid locally — for predictions near x.
Attention Mechanisms in Transformers
If you have ever wondered why ChatGPT, Claude, or Gemini seem to "know" which part of your sentence is most important — attention mechanisms are the answer. And they come with a built-in form of explainability.
In transformer architectures, attention weights indicate how much focus the model placed on each input token when generating each output token. In a sentence like "The bank refused the loan because the credit score was too low," when the model is processing the word "loan," its attention is high on "bank" and "credit score" — the contextually relevant tokens. These attention weights can be visualized and surfaced as an explanation. However, recent research cautions that attention weights do not always correspond perfectly to causal importance — they tell you what the model looked at, not necessarily why that made a difference.
Other Key Techniques Worth Knowing
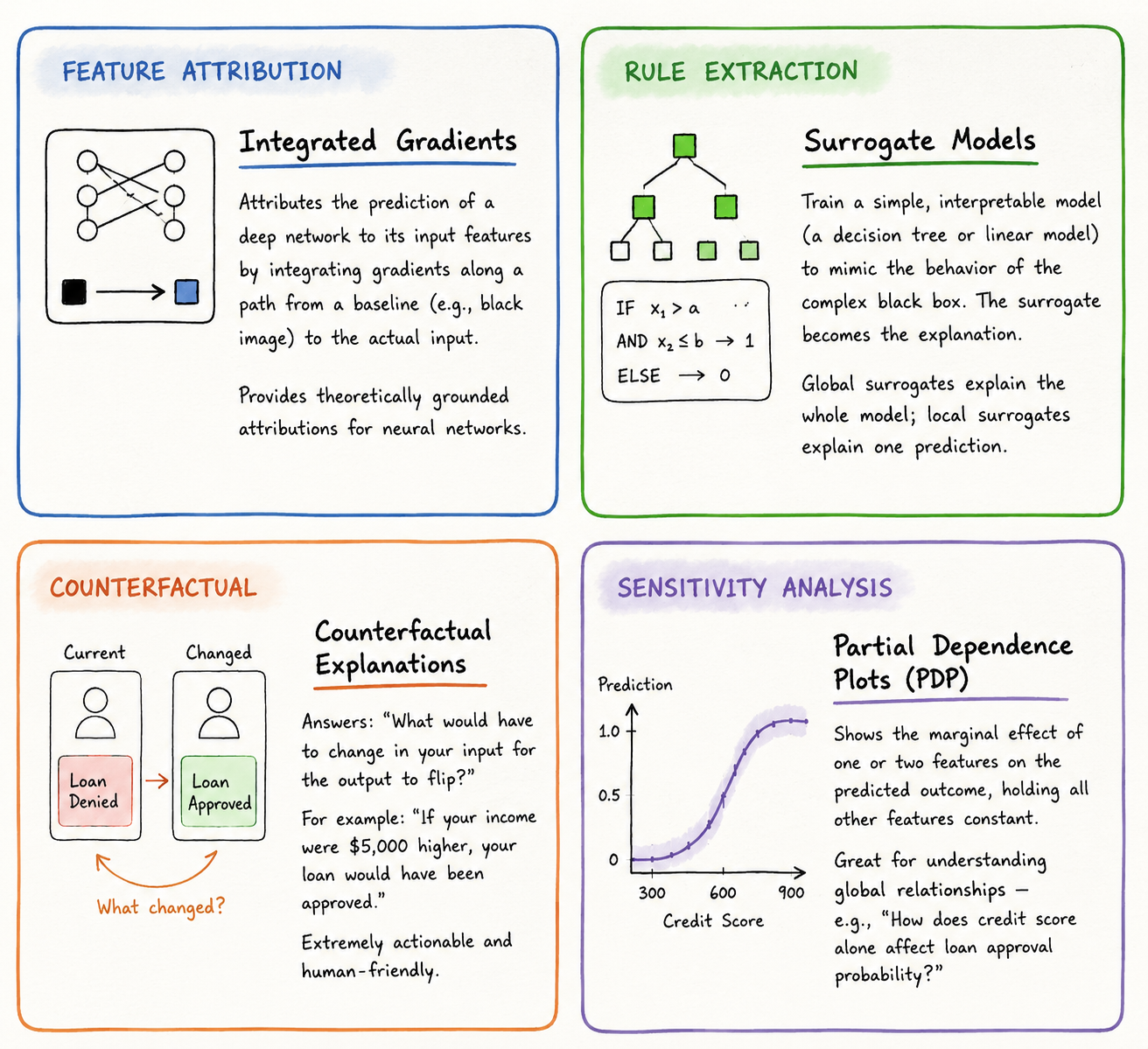
Technical Architecture Behind an Explainable AI System
Most articles on XAI talk about what it does. Here's how it actually gets built — five layers that have to work together.
One thing to clear up first: XAI doesn't replace your model. It wraps around it.
Layer 1: Data — Explainability Starts Before Training
If your features are named pixel_372, your explanations will be useless. If they're named account_age_days, they'll mean something. Semantically meaningful inputs aren't just good hygiene — they're the foundation everything else depends on.
Layer 2: Model Choice — This Locks In Your Options Later
Your architecture determines which explanation tools are even available to you. Gradient boosting pairs naturally with TreeSHAP. CNNs use Grad-CAM. Deep networks lean on Integrated Gradients. LLMs are still the hard case — attention weights give you something, but genuine causal explainability at that scale remains an open research problem.
Layer 3: Explanation Engine — The Working Part
This is where SHAP, Grad-CAM, or whichever algorithm runs. In production, it lives as a separate microservice — you don't want SHAP's coalition computations sitting in your prediction pipeline creating latency. Caching handles repeated inputs cleanly.
Layer 4: Explanation Store — The Audit Trail
Every explanation needs to be logged: timestamp, input hash, model version, explanation payload. In regulated industries, this isn't optional. Under the EU AI Act and GDPR, individuals have a right to a human-readable explanation of automated decisions — and you can't provide that right if you didn't capture the explanation when the decision was made.
Layer 5: Presentation — The Most Underrated Layer
The same underlying explanation needs to look completely different depending on who's reading it. A data scientist wants a SHAP waterfall chart. A loan officer wants two sentences in plain English. A patient wants their risk factors ranked simply. A regulator wants a structured compliance report. Modern XAI platforms handle this translation — but someone has to build it.

What Most Teams Get Wrong
They build a solid model and a solid explanation engine, then neglect Layers 4 and 5. Explanations get generated, never logged, never surfaced to anyone who'd act on them — in a format nobody outside the data team can parse anyway.
XAI isn't done until a non-technical stakeholder reads the output and makes a better decision because of it. Everything before that is just infrastructure.
XAI in Practice: Healthcare, Finance, and Autonomous Vehicles
Healthcare — When a Heatmap Saves Lives
DeepMind and Moorfields Eye Hospital built a system that detects 50+ eye diseases from retinal scans — but the smarter move was showing why it flagged something, not just that it did. Clinicians could look at the highlighted regions and actually evaluate the reasoning rather than blindly trust an output.
A harder lesson came from chest X-ray AI research: some models were quietly learning hospital-specific quirks — scanner types, imaging artifacts — rather than actual disease patterns. They looked great on paper, then fell apart in the real world. That's the kind of failure accuracy scores won't catch. Explainability will.
Finance — Turning "No" into Actionable Feedback
The law is fairly blunt here. GDPR Article 22 and the US Equal Credit Opportunity Act both require that when an algorithm denies someone credit, there has to be a real explanation — not "the model said so."
SHAP makes this workable in practice. A denial becomes: "Your debt-to-income ratio of 42% and two missed payments were the main factors." The CFPB has been clear that model complexity isn't a legal shield, which is pushing the industry toward explainability whether it wants to be there or not.
Autonomous Vehicles — The Black Box That Must Open
Uber's 2018 fatal crash in Tempe, Arizona made one thing painfully obvious: when something goes wrong with an AI system, you need to be able to reconstruct what it was thinking. In that case, they largely couldn't. The fallout pushed AV developers across the board to invest heavily in logging, simulation replay, and audit infrastructure — the unglamorous groundwork that makes after-the-fact accountability possible.
The thread running through all three: XAI isn't a nice-to-have. It's the difference between a system you can audit and one that's just a liability waiting to surface.
"Passengers and other road users deserve to know why a self-driving car suddenly brakes or changes lanes. XAI gives them that right."
— Core Principle, EU Autonomous Vehicle Regulatory Framework, 2025
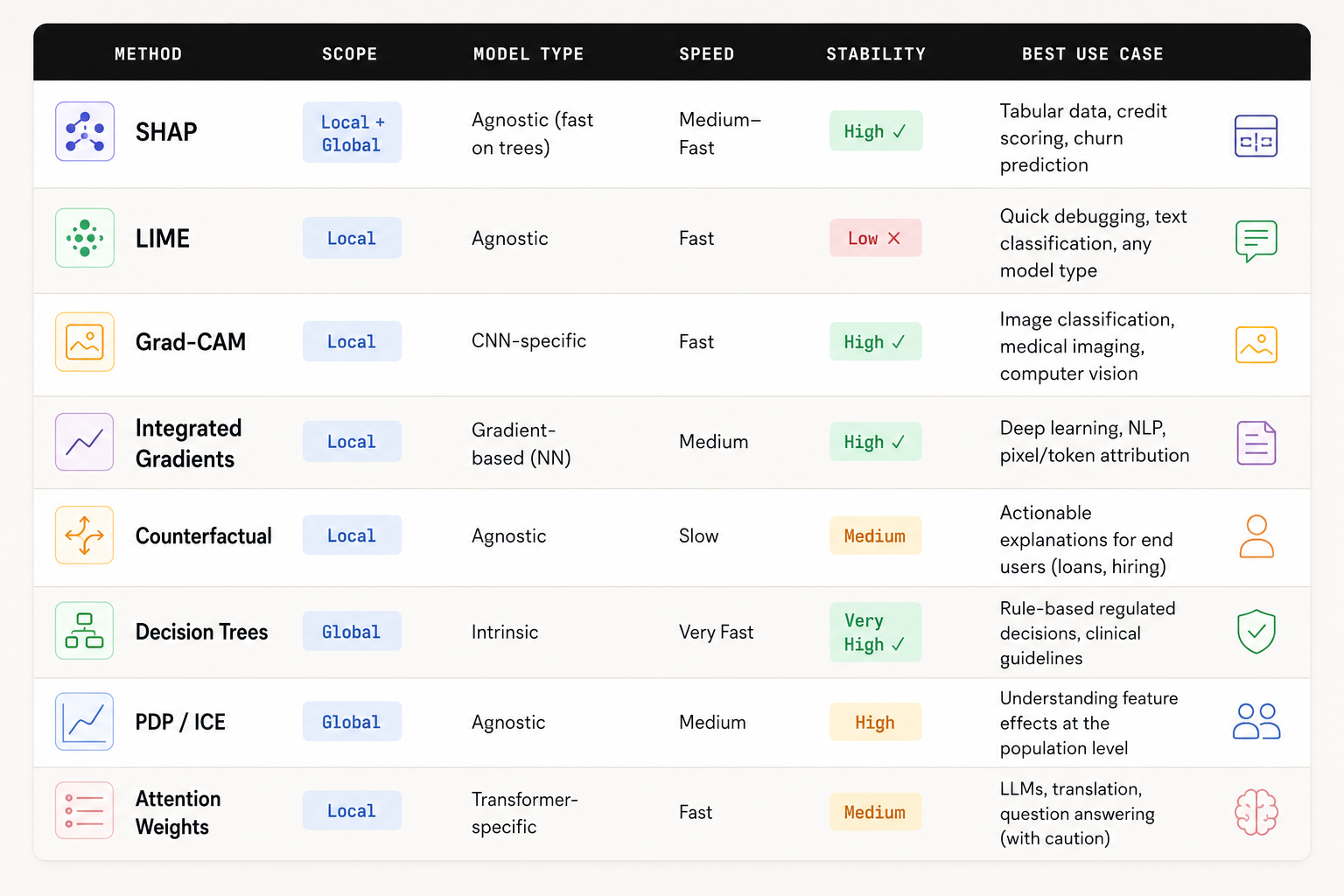
XAI Method Showdown: A Comparison Table
Challenges in XAI
Most XAI content reads like a product brochure. Here is the honest view of where the field genuinely struggles — and why solving these is harder than it looks.
- Faithfulness Problem: SHAP and LIME explain approximations, not actual model logic. A 2020 study showed classifiers can appear unbiased under XAI scrutiny while making discriminatory decisions underneath.
- Rashomon Effect: Hundreds of equally accurate models exist for any dataset — each explaining itself differently. Two data scientists, same problem, technically valid but contradictory XAI outputs.
- Human Interpretation Gap: Most users glance at the top feature, find it plausible, and move on. Explanation becomes a rubber stamp, not oversight.
- LLMs Remain Opaque: At billions of parameters, current XAI methods break down. Why a model generates one sentence over another is still unsolved.
Common Mistakes When Implementing XAI
- XAI as an afterthought. Most teams bolt on an explanation tool post-deployment to tick a compliance box. The result is shallow, misleading outputs. Explainability should be designed from day one — starting with feature naming and data preprocessing.
- LIME in stability-critical settings. LIME's random sampling means the same input can produce different feature rankings across runs. For audit trails or reproducible customer explanations, use SHAP or an intrinsically interpretable model instead.
- Attention ≠ explanation. In transformer models, attention weights show what the model looked at — not what actually changed the output. Presenting them as regulatory evidence of explainability won't survive scrutiny.
- Raw SHAP plots for non-technical audiences. A 25-feature waterfall chart is a data scientist's tool, not a customer letter. Every explanation needs a translation layer suited to its audience.
- Optimising explanation quality over decision quality. If users aren't making better decisions with your explanation than without it, the design needs rethinking — full stop.
Read Also: What Is Janitor AI? Features, Uses and How It Works
Future of Explainable AI: What Is Coming in 2025 and Beyond
XAI has moved from a research curiosity to a regulatory requirement in under a decade. The next phase of its evolution is already underway, and the direction is clear: explanations are getting smarter, faster, more user-adaptive, and more legally enforceable.
- Personalised explanations. One-size-fits-all outputs are disappearing. Next-generation XAI will profile the user — their role, expertise, and context — and render explanations accordingly. A radiologist gets a heatmap. A patient gets plain language. A regulator gets a structured audit trail. Same engine, different outputs.
- Agentic AI demands chain-level explainability. Explaining a single prediction is straightforward. Explaining 20 sequential decisions made autonomously over 10 minutes is not. New XAI frameworks are being built specifically to trace multi-step reasoning chains and summarise entire agent sessions in natural language.
- Regulation is tightening. The EU AI Act is the opening move. The US, UK, Canada, and India are all developing governance frameworks with explicit explainability requirements. By 2026, mandatory explanation logging and third-party auditability will be standard infrastructure — not optional.
- Quantum XAI is emerging. Early research is tackling explainability for hybrid quantum-classical models, signalling the field is expanding well beyond its classical origins.
So What Should You Actually Do? A Practical Framework
You now understand what Explainable AI is, why it matters, how the major techniques work at a technical level, and where the field is heading. The final question is: what do you do with this knowledge?
Here is a practical five-step framework for anyone building, evaluating, or using AI systems:
- Identify your risk level. If your AI affects lives, livelihoods, or safety, explainability is architecture — not an afterthought. Build it into the design document from day one.
- Match method to model. Tabular + gradient boosting → TreeSHAP. Images + CNN → Grad-CAM. Any model needing user feedback → counterfactual explanations. Use the right tool, not the trendiest one.
- Design for your audience. The person reading the explanation is rarely a data scientist. A SHAP plot nobody understands delivers zero value. Build a presentation layer for each specific user type.
- Log at decision time. You cannot retroactively reconstruct an explanation from six months ago. Under GDPR and the EU AI Act, log the input, prediction, model version, and explanation — every time.
- Measure actual impact. Do users make better decisions with explanations than without? If not, the design is broken — regardless of technical sophistication.
The companies and teams who get this right will not just be legally compliant — they will build AI products that people actually trust, use, and rely on. And in a world drowning in black boxes, trust is the ultimate competitive advantage.

Frequently Asked Questions
Blogs and Articles
- Jul 13, 2026
- Technology
What Is Janitor AI? Features, Uses and How It Works
- Janitor AI is a character-based chatbot platform where users create and interact with customizable AI personalities for roleplay, storytelling, and conversations, powered by external AI models via APIs.


- Jul 2, 2026
- Technology

- Jun 30, 2026
- Management

- Jun 27, 2026
- Management