






















 Italy
Italy France
France India
India UAE
UAE Germany
Germany Russia
Russia Malaysia
Malaysia Spain
Spain United States
United States Malta
MaltaWhat is Multimodal AI? Architecture, Working, Benefits, and Use Cases
What is Multimodal AI? Architecture, Working, Benefits, and Use Cases
Artificial intelligence operated in silos for the most part of its history. A model processed text. Another one recognized images. A third model transcribed speech. Each of these were good at one thing and blind to everything else. That limitation now no longer defines the field.
Multimodal AI refers to systems that have the ability to take input from multiple sources of information simultaneously, and also process such data into output in more than one format. This could be achieved using text, images, audio, video, sensor data, and molecular data — all in a single reasoning process. The end product would be an AI with perception more similar to that of humans.
Multimodal artificial intelligence uses text, pictures, sounds, videos, and sensory inputs to achieve better analysis compared to what single-modality AI offers. This innovation has seen these technologies move from research labs to production environments faster than many would have anticipated.
How is Multimodal AI Different from Single-Modality AI?
Conventional approaches to AI operate on a single modality input. For instance, an LLM operates on textual input and generates textual output. A computer vision system will classify or segment an image. All of these approaches work effectively in their domain until another domain becomes involved or the moment a task crosses boundaries.
Consider a clinician reviewing a patient's MRI scan alongside written clinical notes. While a text-only system would miss what's in the image. A picture-only system would be unable to capture the context. This is where a multimodal approach fills in the gaps through a single-pass analysis. Through correlations between different modalities – text, imagery, voice, and environmental data – intention can be understood more accurately by multimodal systems, leading to greater accuracy. This holistic understanding reduces misinterpretation in complex, real-world scenarios.
Please have a look at the tabular comparison between Single-Modality AI and Multimodal AI:
|
Dimension |
Single-Modality AI |
Multimodal AI |
|
Input types |
One data type only: text, image, or audio in isolation |
Text, images, audio, video, and sensor data combined in a single pipeline |
|
Architecture |
Single encoder trained on one modality's feature space |
Modality-specific encoders (e.g., ViT for images, transformers for text) connected via cross-modal attention and fusion layers |
|
Cross-boundary tasks |
Fails or requires multi-step preprocessing to bridge modalities |
Handles cross-modal tasks in a single forward pass with no preprocessing required |
|
Context awareness |
Limited to the information available in one modality's representation |
Correlates signals across modalities, reducing ambiguity and improving intent recognition |
|
Typical failure mode |
Misses information that only exists in other modalities (e.g., a text model ignores chart data) |
Cross-modal hallucination: one modality improperly influences generation about another |
|
Compute cost |
Lower; processing a single data type is architecturally simpler |
Significantly higher; one high-resolution image can consume memory equivalent to thousands of text tokens |
|
Clinical example |
Text model reads notes but cannot interpret the MRI scan; image model reads the scan but lacks patient history |
Processes MRI scan and clinical notes together, enabling cross-modal reasoning for diagnosis |
|
Representative models |
GPT-2 (text) ResNet (vision) Whisper (audio) |
Gemini 2.5 Pro, GPT-4o / GPT-5, LLaMA 4 |
|
Ideal use case |
Well-defined single-modality tasks with clean data and clear input type boundaries |
Complex, real-world tasks where meaning spans multiple data types simultaneously |
How Does Multimodal AI Actually Work? The Architecture Explained
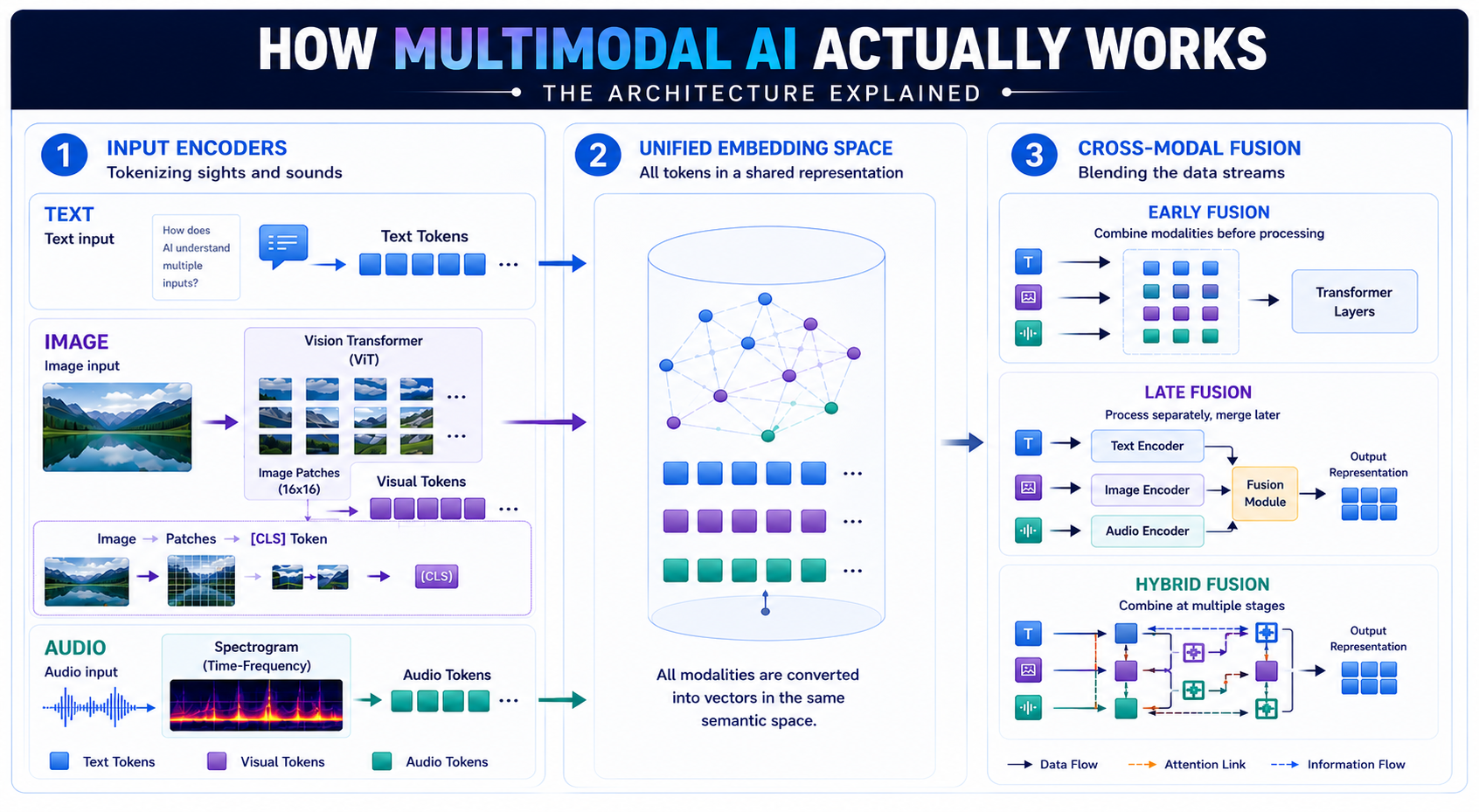
- Tokenizing Sights and Sounds (The Input Encoders)
An AI model cannot read a raw image file or listen to an audio track directly. It must first break them down into data packets called tokens, making them look exactly like text words to the core network.
- Vision Encoder (Vision Transformer / ViT): To process an image, a Vision Transformer (ViT) cuts it into a grid of tiny square patches (usually 16×16 pixels). Each patch is converted into a vector embedding, and a special tracking token, called the [CLS] token, is added to summarize the overall image layout.
- Audio Encoder: Raw audio waveforms are converted into 2D frequency charts called spectrograms. The model tokenizes these visual representations of sound waves, feeding them smoothly alongside text and image tokens into a unified embedding space.
- Blending the Data Streams (Cross-Modal Fusion)
Once all inputs are tokenized, the system must merge them so the model can understand the context. This blending happens through three structural approaches:
|
Fusion Strategy |
How It Works |
Best Used For |
|
Early Fusion |
Raw tokens from text, images, and sound are combined right at the start before any deep processing happens. |
Simple, tightly coupled data relationships. |
|
Late Fusion |
Each modality runs through its own standalone encoder, and only the final answers/features are merged at the very end. |
Independent processing with minimal cross-talk. |
|
Hybrid Fusion |
Early, intermediate, and late combinations are mixed throughout the system, using attention layers to balance weights. |
Complex, deep contextual reasoning. |
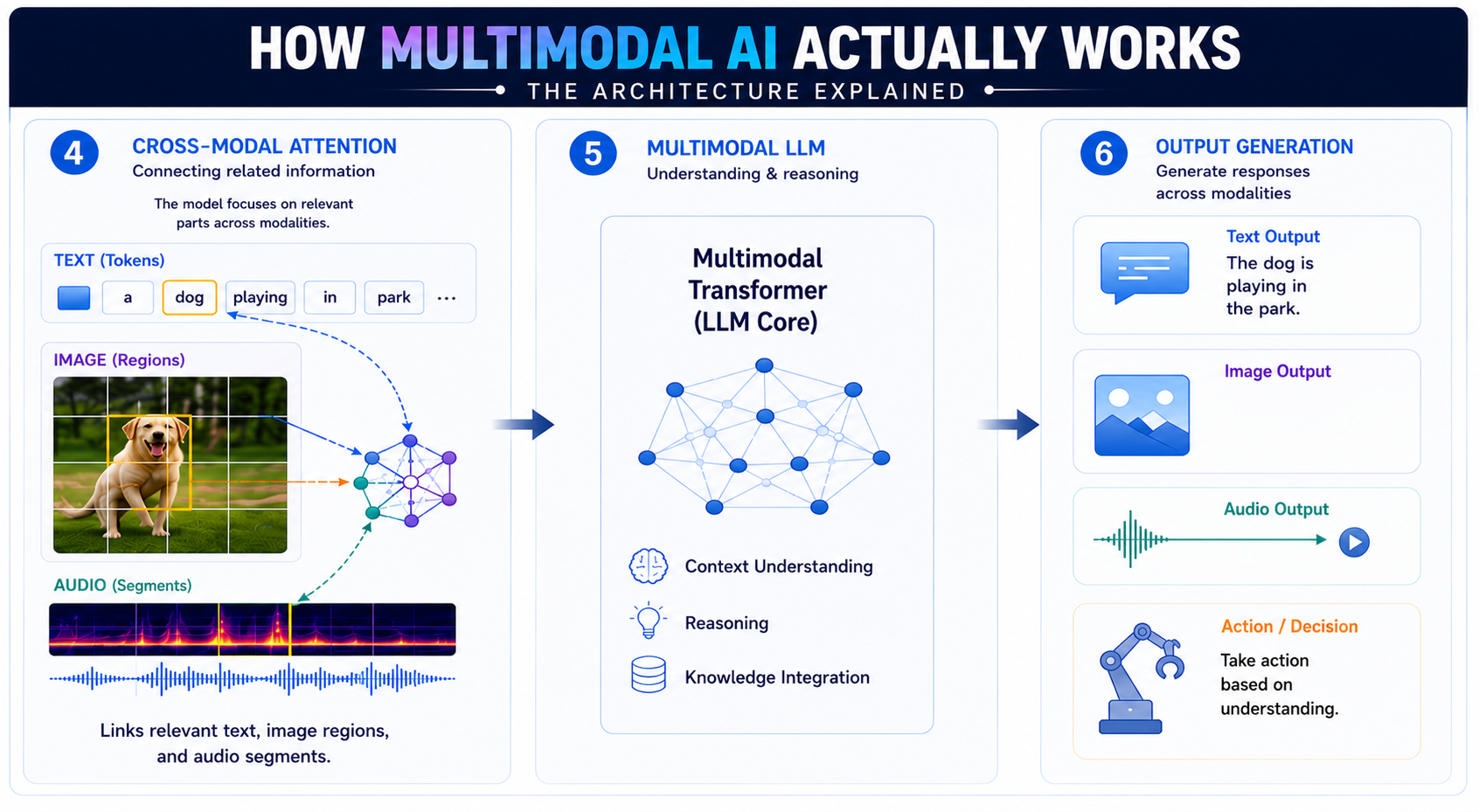
Cross-Modal Attention: It acts as the final connector. Instead of looking at an image in isolation, this mechanism lets the model focus heavily on a specific patch of pixels while at the same time, weighting a related keyword in a sentence.
- Key Research Insight: The Visual Token Bottleneck
While text words are lightweight and cheap to process, it is the visual elements that are computationally punishing. A single high-resolution photograph generates thousands of visual tokens, draining as much memory and compute power as an entire chapter of text.
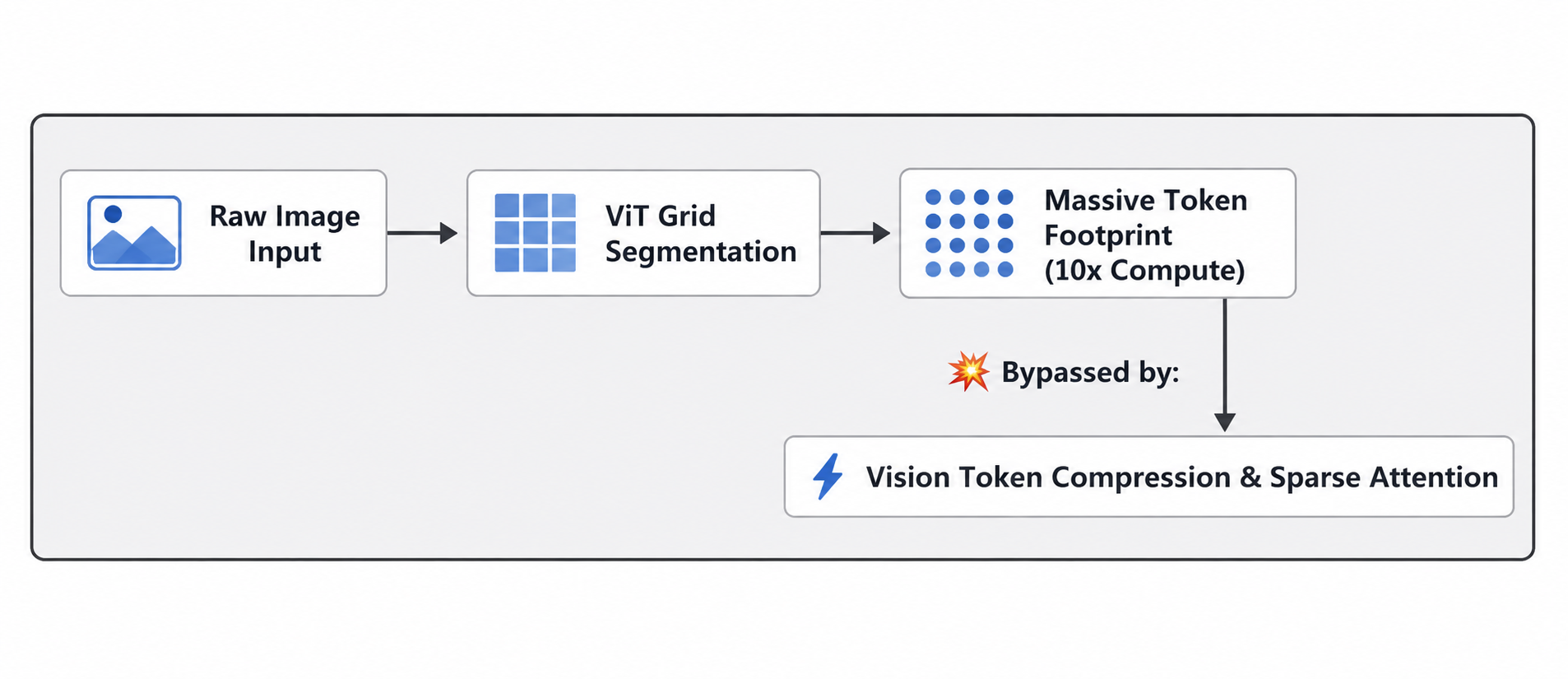
In order to find a permanent fix for this, researchers from Shanghai Jiao Tong University published an extensive benchmark review in the journal Visual Intelligence. Their findings highlight critical breakthroughs for the future of efficient AI design:
- The Scaling Limit: Optimizing a multimodal model isn't the same as optimizing text-only systems; standard LLM compression tricks alone fail to give satisfying results when vision is added.
- Vision Token Compression: The ultimate solution relies heavily on compacting redundant visual data using advanced lightweight connectors (like BRAVE or LDPv2 projectors) before the data ever reaches the primary language brain.
- Sparse Attention Levers: Instead of computing every single pixel-to-text relation, using sparse attention models can successfully reduce inference costs by up to 10x. This makes multi-hour video processing highly scalable and ready for mobile deployment.
Read Also: What Is Janitor AI? Features, Uses and How It Works
Multimodal AI: Technologies Behind the Foundation
Several technical building blocks work together to make multimodal reasoning possible.
- Contrastive Learning
It is one of the earliest and most influential pillars of modern multimodal systems. OpenAI's CLIP and Google's ALIGN established the baseline principle: a dual-encoder architecture processes images and text separately. A contrastive loss function then pulls matching image-text pairs closer together in a shared embedding space while pushing non-matching pairs apart. Instead of deep structural blending, these models perform a geometric alignment of the final-layer representations from separate, pre-trained unimodal encoders.
- Multimodal Instruction Tuning (Capability Extension)
Instruction Tuning extends this foundational alignment into generative capability. A pre-trained vision-language model is fine-tuned on specialized instruction-following datasets. At this stage, it compels the network to learn contextual relationships, helping it solve difficult problems related to image recognition or perform tasks such as answering multi-step prompts based on a video clip, or output structured data (like JSON) directly based on details of visual content.
- Reinforcement Learning from Human Feedback (RLHF)
RLHF and its variant approaches to direct alignment serve as a way of connecting raw capability with human intent. Designers can include human preference data in multiple modalities and decrease occurrences of hallucination, factually inaccurate responses, and irrelevant information in their replies. As a result, the generated text will be directly correlated to the presented image/voice prompt.
- Sensor Fusion (The Physical Layer)
While foundation models operate in digital text and media spaces, sensor fusion serves as the real-world multimodal layer operating entirely below natural language. Being widely used for robotics, industrial monitoring, and autonomous vehicles, sensor fusion involves low-level streaming data from cameras, lidars, radars, and GPS. This geometric and temporal fusion allows for machines to compute instant spatial awareness, better perception of obstacles, and ensures safe operation.
Where Is Multimodal AI Being Applied Today?
Healthcare
Hospitals generate enormous volumes of data. Medical images, clinical notes, lab reports, genetic data, and patient histories. All of this data rarely exists together in one view. Multimodal AI changes that.
The system, by combining these sources, builds a more complete picture of a patient's condition. Key capabilities include:
- Cross-modal alignment between imaging data and clinical text
- Pattern detection across data types that a single-source review would miss
- Support for faster diagnosis and more personalized treatment planning
While true, healthcare remains a high-risk environment. These models which show excellent results in research labs are still found to hallucinate in safety-critical environments. Consequently, this field has moved towards adopting retrieval-augmented generation (RAG) and multi-agent verification systems before any clinical use.
Autonomous Vehicles
A camera cannot perceive fog correctly. A radar cannot read the road signs. None of these sensors alone can do the work. Autonomous vehicles integrate:
- Camera feeds to get all the visual data about roads, lanes, traffic signs, etc.
- Feeds from LiDAR to perceive precise depth and object distance
- Feeds from a radar and a GPS system for motion tracking and position sensing.
This integration enables a vehicle to get a comprehensive understanding of its surrounding environment and operate safely in low visibility or poor weather. If you remove any one modality, it degrades that understanding significantly.
Financial Services (Intelligent Document Processing)
Rather than separating workflows, modern banks are using multimodal AI architectures to process forms, contracts, invoices, and signatures simultaneously. This is validated by the FinErva financial reasoning benchmark. This framework maps multimodal Chain-of-Thought (CoT) reasoning to evaluate unstructured text and visual layout structures concurrently. This integrated approach drastically reduces manual review effort and strengthens fraud detection by treating visual layouts and textual data as a single piece of evidence. (FinErva Study)
Smart Cities (Infrastructure & Disaster Management)
Modern public utility management is depending more on multimodal architectures to counter climate volatility and protect aging urban assets. This framework combines real-time temporal data (weather sensor streams) with spatial dependencies (satellite imagery and city grid graphs), achieving a mathematically proven leap in predicting structural stress over standalone models. This dual-lens analysis helps local governments in major cities like Singapore and Rotterdam change disaster response from reactive maintenance to proactive prevention before a pipeline or power grid fails. (PubMed Central)
Other Industries Adopting Multimodal AI
- Retail and e-commerce — Systems combine product images, browsing behavior, search queries, and written reviews to power personalized recommendations. Shoppers can search using images rather than keywords and receive visually relevant results.
- Customer support — Agents can analyze screenshots, error descriptions, and voice transcripts simultaneously. This combined context helps identify and resolve issues faster than text-only workflows allow.
- Manufacturing — Visual defect detection is fused with machine logs and sensor readings. The system spots production issues and flags maintenance needs before equipment failures occur.
- Legal and professional services — Models bring together contracts, scanned records, emails, and audio transcripts inside a single analytical framework. This cuts the time professionals spend locating relevant information across disconnected sources.
What Are the Most Capable Multimodal AI Models Right Now?
The 2026 model landscape reflects how far the field has matured. Multimodal models, systems that can process text, images, and video together, became reliable enough in 2026 to build production applications around them. What were previously impressive proof-of-concept demonstrations became production tools you could deploy.
- Gemini 2.5 Pro supports 1M+ token context windows and handles text, image, audio, and video inputs. It is tightly integrated with Google's ecosystem and offers deeper cross-modal reasoning with faster inference for large-scale enterprise workflows.
- Meta's LLaMA 4, with variants Scout, Maverick, and Behemoth, supports multimodal input and excels at long-context reasoning. It is designed for both research and commercial use.
- GPT-5 and GPT-4o from OpenAI support multimodal reasoning across text, images, and code, with a unified architecture that enables reasoning across multiple modalities in real time and incorporates improved safety features and reduced hallucinations.
- Anthropic's Claude 4 series, which includes Claude Opus 4 and the high-resolution Opus 4.7, introduces a new paradigm to multimodal space. It combines ultra-high-resolution visual processing with autonomous "Computer Use" tools. This allows agents to look at a desktop screen, move a cursor, click buttons, and type text to execute long-horizon, multi-step tasks across complex software interfaces.
Research has also shown that an 8-billion-parameter model like MMaDA, trained with a unified diffusion-based architecture across text and vision, can outperform LLaMA-3-7B and Qwen2-7B on text reasoning tasks while beating Stable Diffusion XL on text-to-image benchmarks, suggesting that architecture and data curation matter as much as raw scale.
What Are the Biggest Technical Challenges in Multimodal AI?
- Cross-Modal Alignment and Representation
The biggest headache is getting AI to connect words, sights, and sounds logically. This is tough because clean text and messy audio-visual files speak totally different languages. For instance, a single video frame is packed with thousands of distracting background pixels, while a short sentence has a very sharp, direct meaning. Now, because text is much easier for the AI to learn during training, the model often gets lazy, prioritizing simple text data and completely ignoring more complex inputs like audio or video.
- High Computational Complexity and Scalability
Processing high-throughput multimodal data strains hardware. This is due to the quadratic self-attention bottlenecks that render long-form video or high-fidelity audio processing extremely expensive. Furthermore, the massive parameter footprint and need for asynchronous, high-speed data pipelines develop significant bottlenecks in GPU memory and preprocessing.
- Data Inconsistency and Lack of Curated Datasets
Training multimodal AI requires large volumes of accurately paired data, which are difficult to acquire. This often results in poor data quality, lack of temporal alignment in videos, and annotation bias. These challenges, including noisy, web-scraped image-text pairs and biased human labeling of prominent objects, significantly hinder the development of deep reasoning capabilities.
- Hallucination and Cross-Modal Reasoning Failures
Even with good data, AI models struggle to connect different senses logically. If you mention something in the prompt, the model often hallucinates objects that are there in the prompt but are completely absent from the provided image. It also loses track of time in long videos, failing to understand the order of events or how things change over time. Interestingly, while it can read text and identify objects perfectly on their own, it completely fumbles when it has to combine both skills — like trying to read a simple data chart or interpreting a WhatsApp meme.
Read Also: What is Autonomous AI? Capabilities, Architecture, and Enterprise Risks
Where Is Multimodal AI Headed Next?
Progress happening in hardware and edge computing is enabling multimodal AI systems to process text, images, audio, and video in real time. This capability is expected to change the entire trajectory of industries such as autonomous driving, smart cities, healthcare, and industrial automation.
Market momentum is also reflecting this transformation. The global multimodal AI market, valued at $1.73 billion in 2024, is projected to reach $10.89 billion by 2030, growing at a CAGR of 36.8%. (Grand View Research)
On the other hand, there has been an evolution in AI architectural designs. Vision-language models are evolving towards more native multimodal designs. According to Llama 4’s technical report by Meta, the future of multimodal understanding in the industry is entering a new phase, where multimodal understanding is built directly into the model's core design rather than added after training.
There’s little doubt now regarding the future of multimodal artificial intelligence. What remains to be seen is whether progress in the realms of AI alignment, interpretability, and efficiency keeps up with advancements being made in terms of what the technology can do. Success in these areas will determine the confident and safe deployment of these systems in high-stakes environments.

Frequently Asked Questions
Blogs and Articles
- Jul 23, 2026
- Technology
What is SGPA and CGPA? Key Differences, Formula, and How to Calculate
- In college or university, terms like SGPA and CGPA often appear on mark sheets and play a key role in determining scholarships, higher studies, and career opportunities. SGPA measures your performance in a single semester, while CGPA reflects your overall academic journey, progressing more steadily. Recruiters and admission committees evaluate both, making it crucial to understand their differences and learn the correct formulas for calculation. With a strong semester, SGPA can rise quickly, but building a solid CGPA takes consistent effort—both can open doors to internships, global admissions, and scholarships.


- Jul 13, 2026
- Technology

- Jul 10, 2026
- Management

- Jul 2, 2026
- Technology